List of optional exercises#
1. Basic exercises#
Level: Beginner#
Here are some very basic exercises for the fundamentals of python
Play with the notebook#
Take the notebook used for the introduction top python and play with the examples.
Lists and loops#
Write code for printing out a multiplcation table in the form#
Multiplication table for 3:
1 x 3 = 3
2 x 3 = 6
...
Solution#
Show code cell content
def print_multiplication_table(n, max_multiplier=12):
print('Multiplication table for', n)
for i in range(1, max_multiplier + 1):
print(i, 'x', n, '=', i * n)
print_multiplication_table(3)
Fill a list with numbers from 0 to 10 (including 10). Write another loop to add up all the numbers in the list#
Solution#
Show code cell content
lst = list(range(11))
sum_of_lst = 0
for number in lst:
sum_of_lst += number
## or, more concisely
sum_of_lst = sum(range(11))
Write code to print a pattern of * as follows:#
*
* *
* * *
* * * *
* * *
* *
*
Solution#
Show code cell content
for nstars in range(5):
print('* ' * nstars)
for nstars in reversed(range(4)):
print('* ' * nstars)
# or, more concisely
from itertools import chain
for nstars in chain(range(5), reversed(range(4))):
print('* ' * nstars)
Can you generalize your code such that you can print such a pattern for any number of rows?#
Solution#
Show code cell content
from itertools import chain
# We could use 'range(n - 1, 0, -1)' rather than 'reversed(range(n))'
def print_triangle(n):
for nstars in chain(range(n + 1), reversed(range(n))):
print('* ' * nstars)
print_triangle(10)
If, if, if, ….#
In this exercise you will be making geometric pictures using if-clauses. To this end you will program a python function f(x, y) that takes inputs x and y ranging from 0 to 10, and that returns a number from 0 to 5. This function can then be plotted in a color plot.
The color plot we have prepared for you in a helper function (you will learn in day 2 about how to plot things in python):
from helpers import plot_function
As an example, let’s make a function that returns one value if x < 5, and another for x >= 5:
def f(x, y):
if x < 5:
return 1
else:
return 4
We can now use the helper plot_function to represent our function f(x, y) as a color plot:
plot_function(f)
Write your own f(x, y) to reproduce pictures like the ones given below#
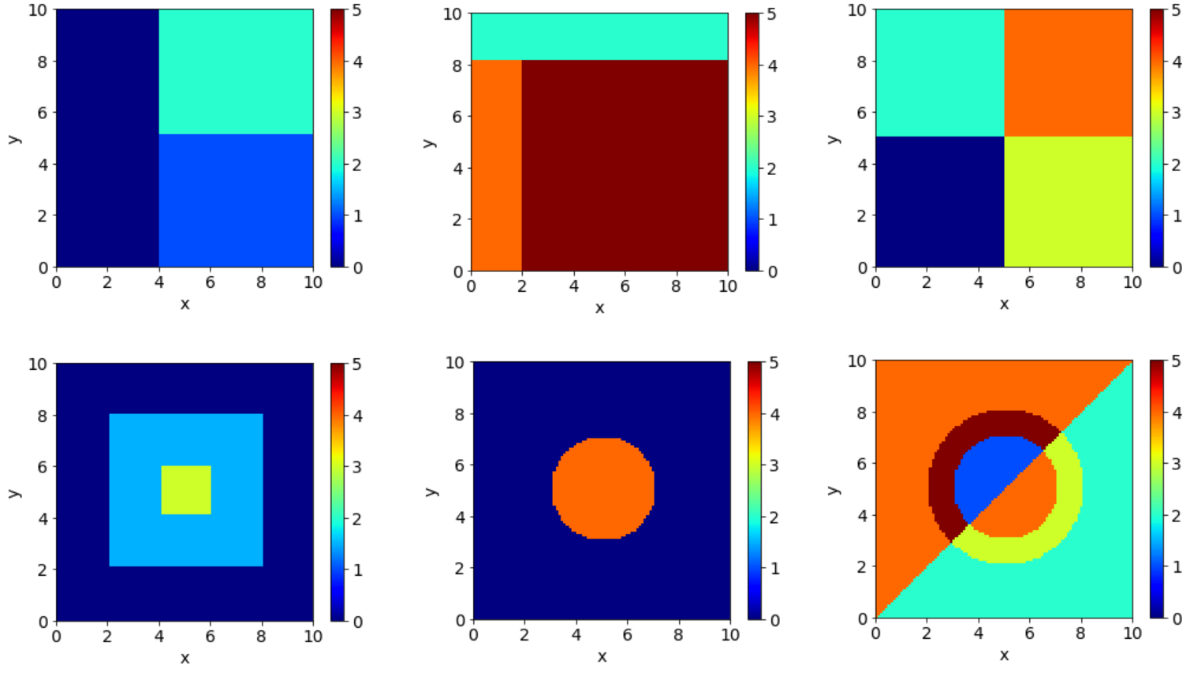
Solution#
Show code cell content
def f(x, y):
if x < 4:
return 0
elif y > 5:
return 2
else:
return 1
plot_function(f)
def f(x, y):
if y > 8:
return 2
elif x < 2:
return 4
else:
return 5
plot_function(f)
def f(x, y):
if x < 5:
return 2 if y > 5 else 0 # use of if-expressions to save a few lines: is this more readable?
else:
return 4 if y > 5 else 3
plot_function(f)
def inside_square(x, y, width, center=5):
x = x - center
y = y - center
return abs(x) < width / 2 and abs(y) < width / 2
def f(x, y):
if inside_square(x, y, width=2):
return 3
elif inside_square(x, y, width=6):
return 2
else:
return 0
plot_function(f)
def inside_circle(x, y, radius, center=5):
x = x - center
y = y - center
return x**2 + y**2 < radius**2
def f(x, y):
if inside_circle(x, y, radius=2):
return 4
else:
return 0
plot_function(f)
def in_upper_diagonal(x, y):
return x < y
# Code re-use 'inside_circle' from previous case
def f(x, y):
if inside_circle(x, y, radius=2):
return 1 if in_upper_diagonal(x, y) else 4
elif inside_circle(x, y, radius=3):
return 5 if in_upper_diagonal(x, y) else 3
else:
return 4 if in_upper_diagonal(x, y) else 2
plot_function(f)
2. Programming for biologists#
Level: Beginner#
Here are two basic problems from a python programming course expecially aimed at biologists
Body mass of dinosaurs#
The length of an organism is typically strongly correlated with it’s body mass. This is useful because it allows us to estimate the mass of an organism even if we only know its length. This relationship generally takes the form:
Where the parameters \(a\) and \(b\) vary among groups, mass is given in kg, and length in m. This allometric approach is regularly used to estimate the mass of dinosaurs since we cannot weigh something that is only preserved as bones.
Different values of \(a\) and \(b\) are for example (Seebacher 2001)
Therapoda (e.g. T-rex): \(a=0.73\), \(b=3.63\) Sauropoda (e.g. Brachiosaurus): \(a = 214.44\), \(b = 1.46\)
get_mass_from_length() that estimates the mass of an organism in kg based on it’s length in meters by taking length, a, and b as parameters. To be clear we want to pass the function all 3 values that it needs to estimate a mass as parameters. This makes it much easier to reuse for all species.
Use this function to compute the mass of T-rex Trix on display in Naturalis, Leiden, which is 13 meters long. Compare to the Camarasaurus they have there, too.
Solution#
Show code cell content
def get_mass_from_length(a, b, length):
return a * length ** b
t_rex = get_mass_from_length(a=0.73, b=3.63, length=13)
camarasaurus = get_mass_from_length(a=214.44, b=1.46, length=20)
DNA vs RNA#
Write a function, dna_or_rna(sequence), that determines if a sequence of base pairs is DNA, RNA, or if it is not possible to tell given the sequence provided. Since all the function will know about the material is the sequence the only way to tell the difference between DNA and RNA is that RNA has the base Uracil (u) instead of the base Thymine (t). Have the function return one of three outputs: ‘DNA’, ‘RNA’, or ‘UNKNOWN’. Use the function and a for loop to print the type of the sequences in the following list.
sequences = ['ttgaatgccttacaactgatcattacacaggcggcatgaagcaaaaatatactgtgaaccaatgcaggcg',
'gauuauuccccacaaagggagugggauuaggagcugcaucauuuacaagagcagaauguuucaaaugcau',
'gaaagcaagaaaaggcaggcgaggaagggaagaagggggggaaacc',
'guuuccuacaguauuugaugagaaugagaguuuacuccuggaagauaauauuagaauguuuacaacugcaccugaucagguggauaaggaagaugaagacu',
'gauaaggaagaugaagacuuucaggaaucuaauaaaaugcacuccaugaauggauucauguaugggaaucagccggguc']
Optional: For a little extra challenge make your function work with both upper and lower case letters, or even strings with mixed capitalization
Solution#
Show code cell content
def dna_or_rna(sequence):
sequence = sequence.lower() # normalize to lowercase
if 'u' in sequence:
return 'RNA'
elif 't' in sequence:
return 'DNA'
else:
return 'UNKNOWN'
for s in sequences:
print(dna_or_rna(s), ':', s)
3. Project Euler#
Level: Beginner - as complicated as you want#
Go to https://projecteuler.net/. It’s a website offering a collection of mathy programming challenges, starting from very simple ones and ending with very hard ones. The first 10-20 problems are a great playground for playing with a new programming language. The problems above 50-100 require advanced knowledge of math and algorithms.
Let’s have a look at the first problem:
Problem 1
If we list all the natural numbers below 10 that are multiples of 3 or 5, we get 3, 5, 6 and 9. The sum of these multiples is 23.
Find the sum of all the multiples of 3 or 5 below 1000.
How can you implement this on a computer? You have to loop over all the numbers and check if they are divisible by 3 or 5. If yes, you add the number.
If you would like to have some more hints, click here.
In similar ways, you can tackle the other Euler problems!
4. Cryptography#
Level: Beginner#
Caesar’s cipher - trial and error#
The following text is encrypted by shifting all letters in the alphabet by a fixed amount (e.g. a shift by 2 would give A -> C, B -> D, …, Z -> B). Decrypt it by trying out all possible shifts! (Just copy the assignment below to use the text in your python program)
encrypted_text1 = """
RW. XMJWQTHP MTQRJX, BMT BFX ZXZFQQD AJWD QFYJ NS YMJ RTWSNSLX, XFAJ ZUTS YMTXJ
STY NSKWJVZJSY THHFXNTSX BMJS MJ BFX ZU FQQ SNLMY, BFX XJFYJI FY YMJ GWJFPKFXY YFGQJ.
N XYTTI ZUTS YMJ MJFWYM-WZL FSI UNHPJI ZU YMJ XYNHP BMNHM TZW ANXNYTW MFI QJKY GJMNSI
MNR YMJ SNLMY GJKTWJ. NY BFX F KNSJ, YMNHP UNJHJ TK BTTI, GZQGTZX-MJFIJI, TK YMJ XTWY
BMNHM NX PSTBS FX F "UJSFSL QFBDJW." OZXY ZSIJW YMJ MJFI BFX F GWTFI XNQAJW GFSI SJFWQD
FS NSHM FHWTXX. "YT OFRJX RTWYNRJW, R.W.H.X., KWTR MNX KWNJSIX TK YMJ H.H.M.," BFX
JSLWFAJI ZUTS NY, BNYM YMJ IFYJ "1884." NY BFX OZXY XZHM F XYNHP FX YMJ TQI-KFXMNTSJI
KFRNQD UWFHYNYNTSJW ZXJI YT HFWWD—INLSNKNJI, XTQNI, FSI WJFXXZWNSL.
"BJQQ, BFYXTS, BMFY IT DTZ RFPJ TK NY?"
"""
To this end, write a function that takes an encrypted text as input as well as a shift, and that then prints the decrypted string.
Hints#
Remember, you can loop over all letters in a string using for c in encrypted_text1:. Also, you can
check if a letter is between “A” to “Z” by "A" <= c and c <= "Z". One way of doing the subsitution is
to generate a dictionary with letters as keys and as values, and then use this to do the substitution in
the for-loop.
There’s a subtle logical mistake that is often done here: you might be compelled to first replace all A’s
in the string with another letter. Say the shift is 1, and that letter is B. Then you will have in your string
two types of B’s: decrypted (from replacing A) and still encrypted (the B from the original encrypted string). If you now replace both type of B’s in the next step, you run into problems …
Solution#
Show code cell content
def decrypt(ciphertext, shift):
ord_A = ord('A')
def decrypt_one(c):
if 'A' <= c <= 'Z': # convert *only* uppercase characters
return chr(ord_A + (ord(c) - ord_A + shift) % 26)
else:
return c
return ''.join(decrypt_one(c) for c in ciphertext)
print(decrypt(encrypted_text1, 21))
%timeit decrypt(encrypted_text1, 21)
Show code cell content
from string import ascii_uppercase
from itertools import cycle, islice
def decrypt2(ciphertext, shift):
# map: ciphertext letters → cleartext letters
codex = islice(cycle(ascii_uppercase), shift, shift + 26)
codex = dict(zip(ascii_uppercase, codex))
codex = str.maketrans(codex)
return ciphertext.translate(codex)
print(decrypt2(encrypted_text1, 21))
%timeit decrypt2(encrypted_text1, 21)
This version uses the string built-in method translate, combined with a translation table that converts between
characters in the ciphertext and the cleartext. This is much faster because it uses Python’s built-in operations.
Caesar’s cipher - frequency analysis#
Level: Intermediate#
The Caesar’s cypher can be broken by frequency analysis: Letters occur in a text with a certain probability. For example, a probability distribution for the English langiage can be found at wikipedia.
Make a probability analysis of the text above. Plot the histogram of the letters using print statements, that looks like
A ****
B ********
C **
etc. From that, determine the shift of the Caeser’s cypher and decrypt it in one go.
Solution#
Show code cell content
from string import ascii_uppercase
def count_characters(text):
text = text.upper() # normalize to uppercase
counts = dict((c, 0) for c in ascii_uppercase)
for c in text:
if c not in counts:
continue # don't count spaces or punctuation
counts[c] += 1
return counts
def print_counts(counts, max_width=None):
# Ensure that each line does not exceed 'max_width' by normalizing the counts.
# We subtract 2 because each line starts with a single character and a space
normalization = 1 if not max_width else (max_width - 2) / max(counts.values())
for letter, count in sorted(counts.items()):
count = int(count * normalization) # round down
print(letter, '*' * count)
counts = count_characters(encrypted_text1)
print_counts(counts, max_width=50)
A step aside: Frequency analysis of English texts#
Level: Intermediate#
In the previous exercise, you were asked to break a cypher using the frequency of letters as given in wikipedia.
You can create such a histogram of frequency of letters yourself. For this, download the text of “Romeo and Juliet” from the file romeo_and_juliet.txt (that was downloade from project Gutenberg), and count the occurences
of all letters A-Z (treating upper case A-Z and lower case a-z the same). Do you find the same result as in the wikipedia article?
Solution#
Show code cell content
## Check out this code reuse!
# This loads the whole file into memory at once, which will not work if the file is larger
# than the available memory.
with open('romeo_and_juliet.txt') as file:
counts = count_characters(file.read())
print_counts(counts, max_width=50)
Substitution cipher#
Level: Intermediate - Advanced#
Now let’s look at a more complicated cipher where we replace (uniquely) every letter by some other letter. This is not just described by a simple shift as before, but now we need to find a different mapping for every letter!
It is a bit difficult to do this by frequency analysis of single letters (although you might identify certain letters). It is easier to do this by doing a frequency analysis of bigrams, i.e. two letter combinations.
Write a code to find out the probability of single letters and of the 10 most frequent bigrams. Use this as input to decypher the following text:
encrypted_text2 = """
"IEGG ZE, DMISTW, DBMI FT RTN ZMOE TQ TNY LPSPITY'S SIPHO? SPWHE DE BMLE XEEW ST
NWQTYINWMIE MS IT ZPSS BPZ MWF BMLE WT WTIPTW TQ BPS EYYMWF, IBPS MHHPFEWIMG STNLEWPY
XEHTZES TQ PZJTYIMWHE. GEI ZE BEMY RTN YEHTWSIYNHI IBE ZMW XR MW EUMZPWMIPTW TQ PI."
"P IBPWO," SMPF P, QTGGTDPWV MS QMY MS P HTNGF IBE ZEIBTFS TQ ZR HTZJMWPTW, "IBMI FY.
ZTYIPZEY PS M SNHHESSQNG, EGFEYGR ZEFPHMG ZMW, DEGG-ESIEEZEF SPWHE IBTSE DBT OWTD BPZ
VPLE BPZ IBPS ZMYO TQ IBEPY MJJYEHPMIPTW."
"VTTF!" SMPF BTGZES. "EUHEGGEWI!"
"P IBPWO MGST IBMI IBE JYTXMXPGPIR PS PW QMLTNY TQ BPS XEPWV M HTNWIYR JYMHIPIPTWEY
DBT FTES M VYEMI FEMG TQ BPS LPSPIPWV TW QTTI."
"DBR ST?"
"XEHMNSE IBPS SIPHO, IBTNVB TYPVPWMGGR M LEYR BMWFSTZE TWE BMS XEEW ST OWTHOEF MXTNI
IBMI P HMW BMYFGR PZMVPWE M ITDW JYMHIPIPTWEY HMYYRPWV PI. IBE IBPHO-PYTW QEYYNGE PS
DTYW FTDW, ST PI PS ELPFEWI IBMI BE BMS FTWE M VYEMI MZTNWI TQ DMGOPWV DPIB PI."
"JEYQEHIGR STNWF!" SMPF BTGZES.
"MWF IBEW MVMPW, IBEYE PS IBE 'QYPEWFS TQ IBE H.H.B.' P SBTNGF VNESS IBMI IT XE IBE
STZEIBPWV BNWI, IBE GTHMG BNWI IT DBTSE ZEZXEYS BE BMS JTSSPXGR VPLEW STZE SNYVPHMG
MSSPSIMWHE, MWF DBPHB BMS ZMFE BPZ M SZMGG JYESEWIMIPTW PW YEINYW."
"YEMGGR, DMISTW, RTN EUHEG RTNYSEGQ," SMPF BTGZES, JNSBPWV XMHO BPS HBMPY MWF GPVBIPWV
M HPVMYEIIE. "PWIEYESIPWV, IBTNVB EGEZEWIMYR," SMPF BE MS BE YEINYWEF IT BPS QMLTNYPIE
HTYWEY TQ IBE SEIIEE. "IBEYE MYE HEYIMPWGR TWE TY IDT PWFPHMIPTWS NJTW IBE SIPHO.
PI VPLES NS IBE XMSPS QTY SELEYMG FEFNHIPTWS."
"BMS MWRIBPWV ESHMJEF ZE?" P MSOEF DPIB STZE SEGQ-PZJTYIMWHE. "P IYNSI IBMI IBEYE PS
WTIBPWV TQ HTWSEANEWHE DBPHB P BMLE TLEYGTTOEF?"
"P MZ MQYMPF, ZR FEMY DMISTW, IBMI ZTSI TQ RTNY HTWHGNSPTWS DEYE EYYTWETNS."
"""
Hint: Don’t try to do everything in one go. As you have identified certain letters, substitute those in the text, and then guess other letters. Decrypt the text thus step by step.
Solution#
Show code cell content
def decrypt_substitution_cipher(ciphertext, key):
"""Return cleartext, using a substitution cipher with a given key.
Parameters
----------
ciphertext : str
The text to decrypt
key : dict, str → str
Map from the ciphertext characters to the cleartext characters.
Any characters that appear in 'ciphertext' but do not appear in 'key'
remain unchanged in the cleartext.
"""
return ciphertext.translate(str.maketrans(key))
from string import punctuation
from itertools import product
def count_bigrams(text):
# normalize to uppercase
text = text.upper()
# Normalize all punctuation characters to a single space because these all
# mark the beginning/end of words. This is probably incorrect for hyphenation,
# but we hope that hyphenated words will be rare enough to not affect our analysis
replace_punctuation = dict((p, ' ') for p in punctuation)
text = text.translate(str.maketrans(replace_punctuation))
all_bigrams = product(ascii_uppercase + ' ', repeat=2)
counts = dict((c, 0) for c in all_bigrams)
del counts[' ', ' '] # don't count consecutive punctutation
for a, b in zip(text, text[1:]): # each character and its following character
if (a, b) not in counts:
continue # don't count punctuation
counts[(a, b)] += 1
return counts
from operator import itemgetter
def top_counts(counts, n=10):
sorted_counts = sorted(counts.items(), key=itemgetter(1)) # sort by count
return dict(sorted_counts[-n:]) # other functions expect 'counts' as a dict
# Here we re-us
print_counts(top_counts(count_bigrams(encrypted_text2)))
with open('romeo_and_juliet.txt') as file:
top_bigrams = top_counts(count_bigrams(file.read()))
print_counts(top_bigrams, max_width=50)
5. Babynames#
Level: Intermediate#
The file babynames.txt contains data on all names given to male children in the Netherlands in 2015 (from SVB. I apologize for only giving boy’s names - for some reason the SVB didn’t give a file with all girl’s names)
Read the file and do some analysis of the data:
Find the most common name. How many percent of Dutch male children were named like this in all of 2015?
Find the shortest/longest name
Find the name with the most special characters (“special” = not A-Z)
Find the top 20 names, and give the percentage how often children were named like this. What is the total percentage of the top 20 names, i.e. how often are top 20 names given?
Solution#
Show code cell content
def parse_line(line):
*name, count = line.split() # the name may contain whitespace, but the count may not
return ' '.join(name), int(count)
with open('babynames.txt') as file:
names, counts = zip(*(parse_line(line) for line in file))
from operator import itemgetter
count, most_common_name = max(zip(counts, names))
print('The most common name is', most_common_name)
print('The shortest name is', min(names, key=len))
print('The longest name is', max(names, key=len))
def count_specials(s):
return sum(not char.isalpha() for char in s)
print('The name with the most special characters is', max(names, key=count_specials))
import heapq
top_counts, top_names = zip(*heapq.nlargest(20, zip(counts, names)))
pct_named = 100 * sum(top_counts) / sum(counts)
print('the 20 top names are:', ', '.join(top_names))
print()
print(f'boys were named this way {pct_named}% of the time')
6. Find the zero of a function#
Level: Intermediate to Advanced#
Write a function to find the zero of a mathematical function \(4f(x)\) within an interval \([a, b]\), when \(f(a)\) and \(f(b)\) have opposite sign (this makes sure there is at least one zero in this interval.
Find this zero by bisecting the interval: Take the middle point \(c\), and find out which interval now must have the zero by comparing the signs of the \(f(a)\), \(f(b)\), and \(f(c)\). Iterate this procedure to zoom in on the zero.
Write a python function find_root(f, a, b) that implements this procedure. This python function should take another python function f as input, as well as two numbers a and b.
Possible extensions, optional:
Have another input parameter specifying the numerical accuracy with which you want to find the zero.
Check the user input to make sure
find_rootcan actually find a root.
Solution#
Show code cell content
import functools
def find_root(f, a, b, tol=1E-8):
"""Finds a root of 'f' in the interval '(a, b)' to an accuracy of 'tol'.
If there are 0 or an even number of zeros in the interval, this function will raise
a 'ValueError'. This function does not detect whether there are > 1 zeros in the
interval.
"""
# Memoizing is advantageous for all but the most trivial of functions
# We only need to store (f(a), f(mid), f(b)), so we cap the size of the cache at 3
f = functools.lru_cache(maxsize=3)(f)
def has_root(a, b):
return f(a) * f(b) <= 0 # sign of f(a) is different to f(b), **or** either one is exactly zero
# Ensure we have 1 (or at leas)
if not has_root(a, b):
raise ValueError(f'function {f} has no (or > 1) zeros in the interval ({a}, {b})')
# quick return for the edge case
if f(a) == 0:
return a
if f(b) == 0:
return b
while abs(a - b) > tol:
mid = (a + b) / 2
# quick return for the edge case
if f(mid) == 0:
return mid
# bisect the interval
if has_root(a, mid): # go left
b = mid
else: # go right
a = mid
return (a + b) / 2
find_root(lambda x: x, -1, 1) # catches the edge case where the root is on a boundary
find_root(lambda x: x, -1, 1.1) # still within 'tol' of the true value
find_root(lambda x: x**2 - 1, -2, 0.5)